


If you work in a marketing agency, then finding the time to understand and implement efficient data tools and architecture can be tricky. It’s one of the things we hear agencies struggle with time and time again.
The most ambitious agency marketers have a dizzying amount of spinning plates on the go at any given time, and sometimes that means data ops get put on the back burner. However, with clients increasingly demanding a data-driven approach, streamlining the way you manage all your clients across your data stack is critical for effective client reporting.
There are a few different ways to set up a data pipeline architecture to manage multiple clients’ data. So, to help you better understand which one might be right for your agency, we’ve laid out the four most common data architecture setups, and their use cases. But first, let’s take a look at some of the key priorities you need a good grasp on to help decide the best data pipeline architecture for your agency.
Key priorities to consider when deciding on your data pipeline architecture
Every agency is different, and that means the ideal agency data stack will look different depending on a whole host of variables. However, there are a few common setups that you can use as a jumping-off point when considering what data pipeline architecture is best for your agency.
The general process is the same for all of these setups — you’re pulling the relevant data, standardizing it, and sending it off to your preferred destination, whether that’s a data warehouse, a BI tool, an analytics platform, or an in-house analytics solution.
It’s the way that these data pipelines are structured that differs between agencies, as this dictates how data is grouped before it gets sent on to its end destination. More importantly, it’s also going to define how you’ll scale your agency as it grows.

Before you get into what data architecture you need, ask yourself the following questions:
- Security and privacy - How important is it to keep client data siloed?
- Agency size - Does your agency operate in multiple markets?
- Data maturity - Does your agency have the capacity to analyze marketing data at a holistic level?
- Existing data stack - Does your agency already have a data warehouse and an in-house solution that you’re working with?
The 4 most popular data pipeline architecture setups for agencies
1. By client
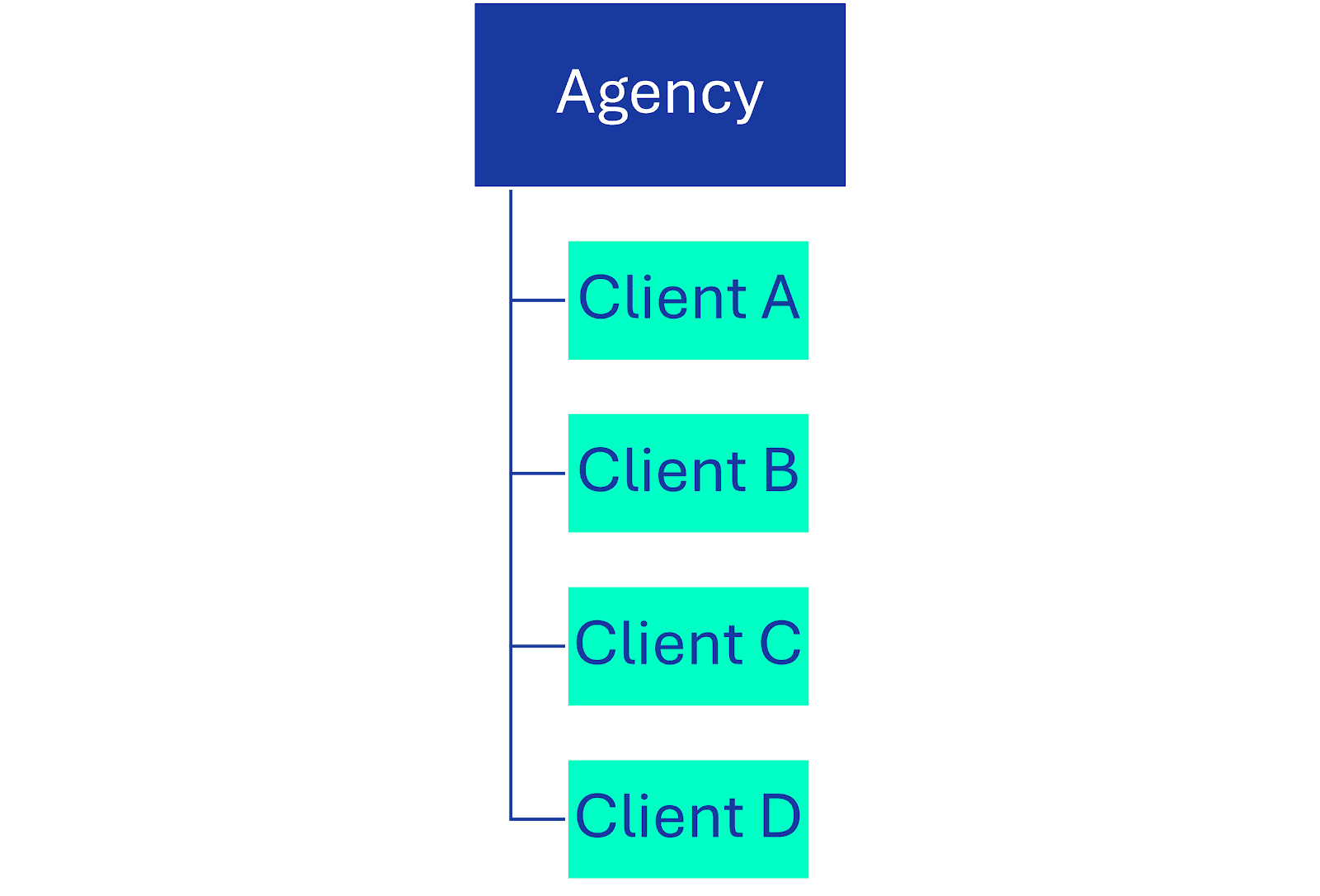
- Data is organized by client
- User permissions or authorizations are governed at the client level
- Ideal for simplifying the separation of client data
- Most common for single-market agencies
Grouping data pipelines by client is the most popular setup we see — especially for agencies operating in a single-market. There are a few reasons so many agencies choose this setup, but crucially it means that client data remains separated, which simplifies privacy and security concerns.
On the client side, this data pipeline architecture offers the security of minimizing data sharing because of the client data silos. On the agency side, you still get the benefit of a high-level cross-client overview of all your data across markets, including trends and benchmarks that can help guide budget decisions.
For example, by filtering Google’s data you can see overall trends and review if CPC has gone up over the last few years, and determine either that Google is increasing prices, or you’ve been targeting more expensive keywords.
For agencies, it makes sense to have as many global enrichments as possible so that data can be compared like for like across clients, markets, and channels. So, if you can collectively agree on a template for client reporting, this will make the model much more scalable — however, for agencies with a more bespoke approach to each client, it’s also a flexible infrastructure to customize.
2. By market
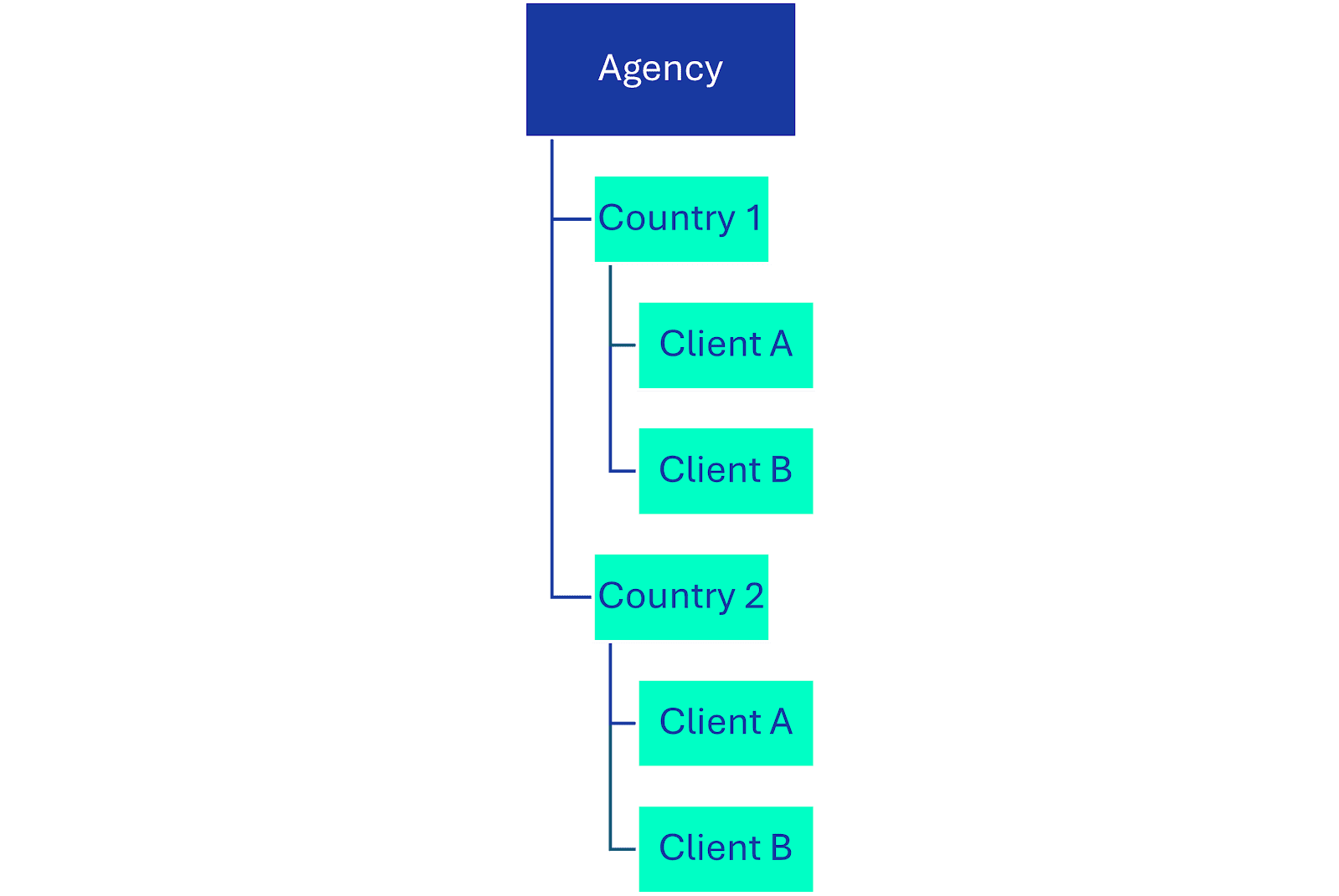
- Data is organized by country or region with client teams grouped within each market
- Cross-market reporting for each client is done at the overall agency level
- Ideal if you have separate contracts for individual markets across the same clients
- Most common for global agencies
For global agencies that work across multiple regions, separating data pipelines by market is a great option. This is a similar setup to the first one, except client workspaces all fall under the umbrella of whichever market they’re attributed to.
If you’re setting up an architecture like this, the best way to go about it is to choose a few model markets that best represent the data processes you want to replicate and use these as a template for other markets.
Of course, there will always be some kinks to iron out when you’re implementing a large-scale model like this one. Automated to transform formats for different languages and currencies can help here, but for more complex variations across regions, it’s important to reach a consensus on the most efficient template while considering the differing perspectives of each market.
The goal is to be able to compare markets like for like. While it may take some discussion to settle on your preferred metric definitions and data processes, putting in this groundwork early on is well worthwhile, as it will allow for accurate comparison across all of your markets.

3. By channel
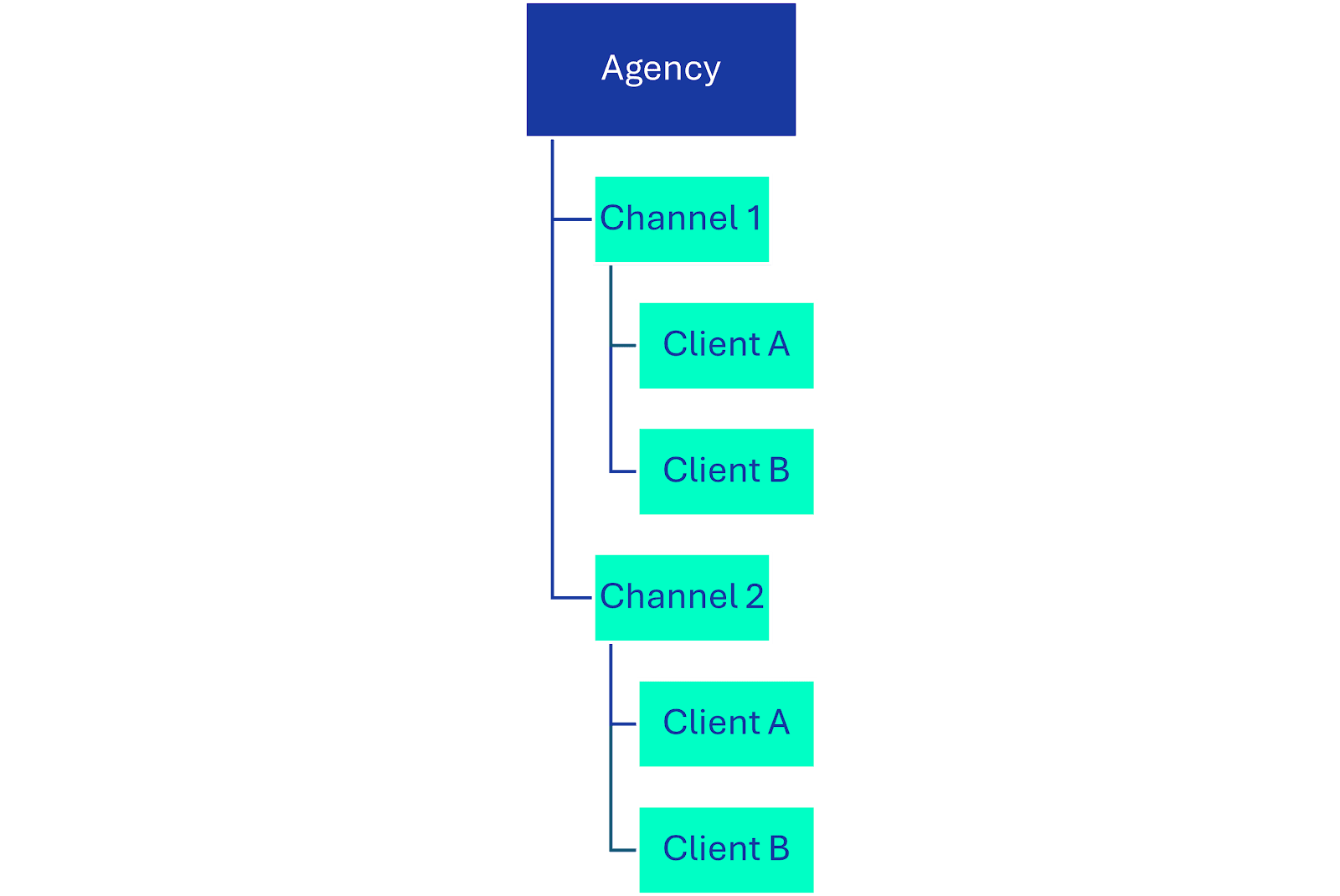
- Data is organized according to specific channels and the teams that work on them
- Cross-channel reporting for each client is done at the overall agency level
- Ideal for agencies with specialized teams
This is a less common setup than the previous two options, however, it can work extremely effectively in agencies that have specialized teams working on specific channels or platforms. For example, an agency with this kind of setup might have a team for search, a team for programmatic, a team for social, etc.
If the directors for each of these teams only want to see their data and budget information when working in their workspace, then separating workspaces by channel makes the most sense. The downside to this is that it can make visibility across departments more complicated, and obstruct a more holistic view of marketing activities.
This setup also lends itself to a more streamlined architecture where you have one datastream per channel for all your clients instead of one datastream per channel per client. While it’s more common for agencies to maintain separate data streams for each client, having one data stream for each channel and then segmenting it afterward can be hugely beneficial — so, for example having one Google Ads datastream that brings in all your clients’ Google Ads data, and then separating this out by client afterward.
One major issue that this setup helps tackle is authorizations — if you’re using an integration tool and the person who created the account leaves your agency, the account gets shut down, and everything has to be reauthorized and reconnected.
Having one global authorization rather than one per client allows you to control permissions, control which customers are in your system, and easily add new customers without having to go through each data stream. However, depending on your clients, getting a global authorization can be a challenge.
4. Combination
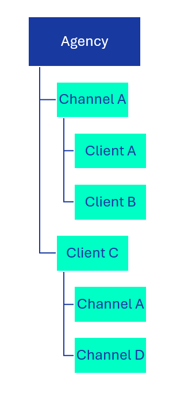
- Data is organized according to a combination of structures
- Depending on the structure, overall client reporting most likely to be done at the agency level
- Ideal for agencies that want a customizable and flexible approach
As you’ve probably guessed, this option is a combination of the above three structures and, if we’re honest, what many agency setups tend toward, as all agencies are different and have specific needs and requirements.
Templating and blending elements from structuring data by client, market, and channel forms a versatile data infrastructure for agencies that have a more bespoke approach. Often agencies will need a combination tailored to diverse client portfolios and team specializations to optimize efficiency, security, and insights.
By considering factors like security concerns and existing infrastructure, agencies can design a flexible data architecture that fosters growth and innovation, ensuring competitiveness and excellence in a data-driven landscape.


