


The world runs on data. According to Forbes, over the last two years alone 90% of the data in the world was generated, and each day, 2.5 quintillion bytes of data are created — and that number keeps growing.
Businesses that are ready to deal with these huge waves of data effectively will be the ones that thrive over the next decade. So, data integration and data ingestion are two key concepts to understand. However, these are often confused with one another. While data integration (especially the term ETL) has been a common concept for quite some time now, data ingestion is a relatively new piece of jargon.
In a world where data has become the most valuable asset, understanding the difference between data ingestion and data integration is critical to find the right approach for your business. In this article, we explore the differences between these two processes, their benefits, and challenges.
What is data ingestion?
Data ingestion is the process of obtaining and importing data for immediate use or storage in a database.
In other words, data ingestion is used to harmonize and integrate multiple data sources into a single place of access to eradicate data silos.
This process involves collecting data from different sources, such as social media, cloud-based services, IoT devices, etc., and making it available for analysis. Data ingestion can be done manually, but it's often automated through data ingestion tools that extract and load data.
Let’s look at an example: a marketing team might need to report on campaign data to be able to make decisions on optimizing spend across a range of ad platforms. But as is often the case, data is being collected and stored in multiple different systems. In order to get the full picture of campaign activity, a centralized database or data warehouse is needed, with data from all of these sources harmonized and ready to be used as a single source of truth. To achieve this, data ingestion is key.
The data ingestion process
First, let’s discuss the process. The data ingestion pipeline involves the following steps:
- Data collection: Data is collected from various sources such as ad platforms, CRMs, databases, web pages, etc.
- Data filtering: Data is filtered to remove any irrelevant information.
- Data harmonization: Columns and data types are harmonized into a format that can be easily analyzed when multiple sources come together.
- Data loading: Data is loaded into a centralized repository or database.
Types of data ingestion
In general, there are three main approaches to data ingestion, and the best strategy for your company will depend on your data needs.
- Batch ingestion: Data is ingested in batches periodically, for example hourly, daily, or weekly.
- Real-time ingestion: Data is ingested as it’s generated, providing immediate access to the most up-to-date information.
- Event-based ingestion: Data is ingested in response to specific events or triggers, such as a customer making a purchase.
Challenges of data ingestion:
There are several challenges associated with data ingestion, including:
- Quality: Ensuring that data is accurate and consistent can be difficult.
- Latency: Processing large volumes of data can take time, resulting in latency.
- Scalability: As the volume of data increases, it can become challenging to scale the infrastructure to accommodate the data.
What is data integration?
Data integration is the process of combining data from different sources into a unified view.
This process involves mapping data from different sources to a common data model, transforming the data, and loading it into a new system. Data integration is focused on creating a unified view of data, regardless of its source.
Data integration process
The data integration process involves the following steps:
- Data profiling: Data is profiled to understand its structure, relationships, and quality.
- Data mapping: Data is mapped to a common data model to ensure consistency and accuracy.
- Data transformation: Data is transformed to meet the requirements of the target system.
- Data loading: Data is loaded into the target system.
Types of data integration:
There are many different types of data integration architecture, including:
- Manual integration: Data is integrated manually using tools such as spreadsheets and databases.
- ETL (Extract, Transform, Load): Data is extracted from different sources, transformed into a common format, and loaded into a target system.
- ELT (Extract, Load, Transform): Data is extracted from different sources, loaded into a target system, and then transformed.
- API integration: Data is integrated using data integration software through APIs, which enable different systems to communicate with each other.
Challenges of data integration:
There are several challenges associated with data integration including:
- Data quality issues: Ensuring data is accurate and consistent across different sources can be a challenge.
- Data governance: Managing and governing data across different systems can be difficult.
- System compatibility: Ensuring that the new system is compatible with existing systems can be a challenge.
Data ingestion vs. data integration: What’s the difference and which one should you use?
While data ingestion and data integration share similar goals, they approach data movement in different ways. The data ingestion pipeline is focused on bringing data into a system as quickly and efficiently as possible, while data integration architecture is focused on blending data from various sources before transferring the data. Deciding which approach to use depends on your business requirements and goals.
Data integration and data ingestion may sound quite similar so far, but they do have one key difference. First, let’s look at a visual example of data integration:
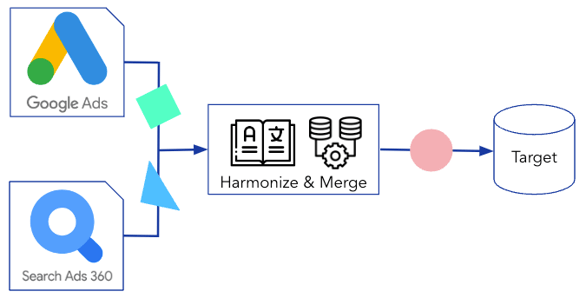
Data is being fetched from Google Ads and Google Search Ads. Google Ads holds detailed ad and keyword data about paid search campaigns from Google and Google Search Ads 360 holds cost and conversion data about paid search.
After the data is fetched, it is first harmonized to ensure consistent column headers and data types and then merged.
Next, the harmonized and merged data is transferred into a database (the target).
Now let’s have a look at a data ingestion example:
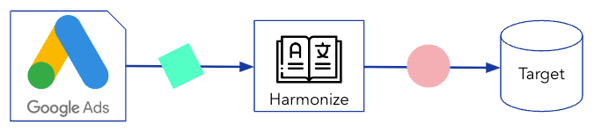
Here, Google Ads data is being collected, harmonized, and transferred into a database.
This can happen for multiple data sources in parallel. As long as the data is harmonized, the data is ready for any type of merging and analysis directly in the database.
The confusion around both concepts stems from the fact that, more recently, cloud computing has made it possible to flip the final two stages of the ETL process so that loading happens before the transformation. This is known as ELT.
So, when you're working with combining data from multiple systems before loading it into a database, it's data integration. But if you're just getting your harmonized data from X to Y, it's data ingestion.
The importance of automating your systems
One last thing, whether you choose data integration or data implementation, automating these processes with data integration tools and data ingestion tools is key to helping organizations streamline their data management workflows. By automating these processes, organizations can save time and resources while ensuring data security, accuracy, and consistency. Automated systems can also eliminate the need for manual data entry, which helps companies reduce the risk of errors.
Ultimate reporting with one true data source
Data ingestion and data integration are both critical components of any successful data management strategy. By understanding the differences between these two approaches, you can choose the right strategy for your business needs and goals. With the right approach and a solid data governance strategy in place, you can ensure that your data is accurate, consistent, and available when you need it, helping you make better business decisions and drive better outcomes.

